I have experience in designing and implementing databases, along with strong skills in Structured Query Language (SQL) for managing and querying data. I am proficient in managing databases using PostgreSQL, SQLite, MySQL, and ArcGIS Enterprise Geodatabase, allowing me to handle various database management tasks efficiently and effectively.
Data Management System for Fish Species and Fishing Sites at George Washington Birthplace National Park
Problem
In this project, I addressed the need for a structured, efficient way to store and manage data related to both game and non-game fish species, as well as fishing sites, in George Washington Birthplace (GEWA) National Park. The goal was to create a database that could store detailed information about various fish species and fishing locations, providing easy access for park researchers and conservationists to analyze species distribution and monitor habitat health. This database would facilitate better decision-making in fish population management and conservation efforts within the park.
Analysis
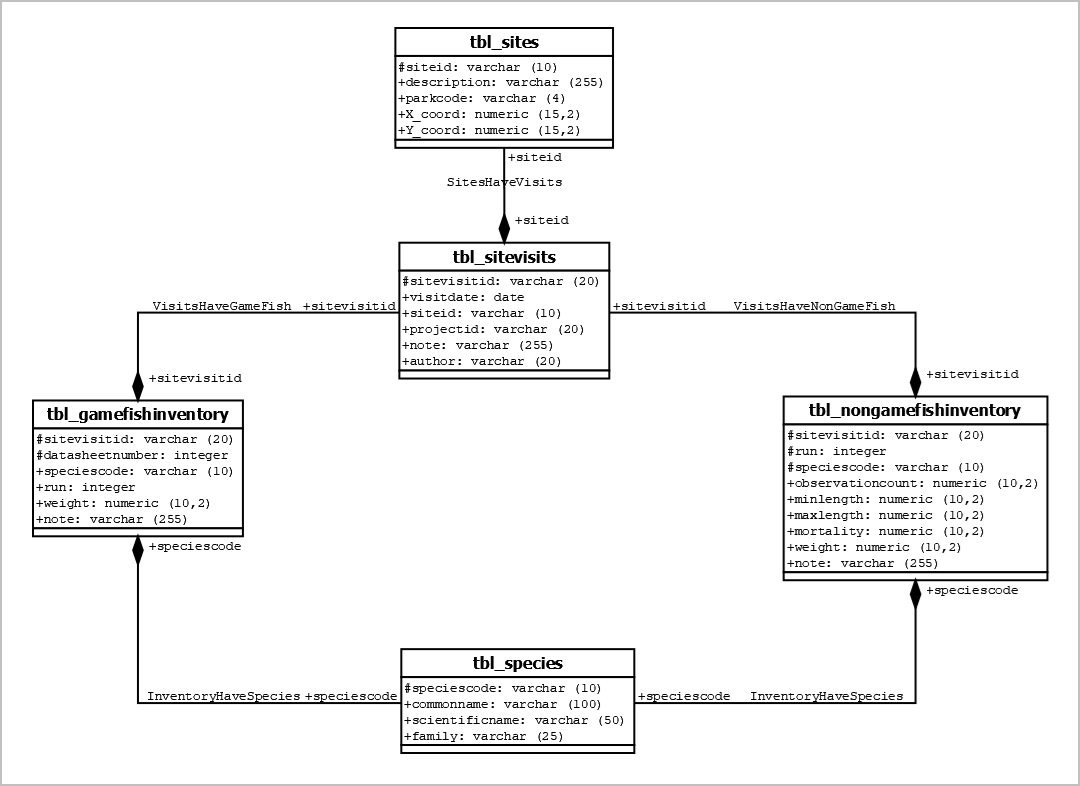
To address the problem, I designed a comprehensive database system using PostgreSQL. The process began by creating an Entity-Relationship (ER) diagram to model the relationships between fish species, fishing sites, and relevant attributes such as habitat type and location. Additionally, a Unified Modeling Language (UML) diagram was developed to visualize the system’s structure and operations. After finalizing the database design, I implemented the schema by writing SQL commands to create the necessary tables, establish relationships between entities, and populate the database with data. Views were created to simplify querying and reporting, enabling users to generate specific reports on species distribution and site information efficiently.
Results
The outcome of the project was a fully functional PostgreSQL database that allows for the efficient storage and retrieval of data regarding fish species and fishing sites within the park. The database includes tables that store comprehensive details on species characteristics, habitats, and site locations. The system also supports queries that retrieve species-specific or location-specific information, which can be useful for research and conservation purposes. The ER and UML diagrams visually depict the data structure and workflow, making the system easy to understand and expand upon as needed. The UML diagram in Figure 1 shows the names of the tables, their attributes, and the datatype of each attribute.
Reflection
This project has helped me sharpen my database design and implementation skills, particularly in structuring complex datasets related to environmental and biological research. Through this project, I learned how to translate real-world conservation needs into a robust data management system, focusing on efficient data storage, relationships between biological entities, and ensuring ease of access for end users.
————————————————————————————————————-
Enhancing JC Raulston Arboretum’s Database Systems
Problem
The JC Raulston Arboretum (JCRA) maintained two primary databases: a FileMaker database for non-spatial data and a Postgres database for spatial data. A critical issue was the lack of seamless synchronization between these databases, causing up to a one-minute delay for updates to propagate from FileMaker to Postgres. This delay hindered operational efficiency and real-time data management. Additionally, the Postgres spatial database was disorganized, containing fragmented layers, empty tables, and redundant data, making it challenging to manage and analyze spatial information effectively. One of the main tasks of my capstone project was to resolve the synchronization delay, reorganize and clean up the spatial database, and establish an enterprise geodatabase to improve data management and accessibility.
Analysis
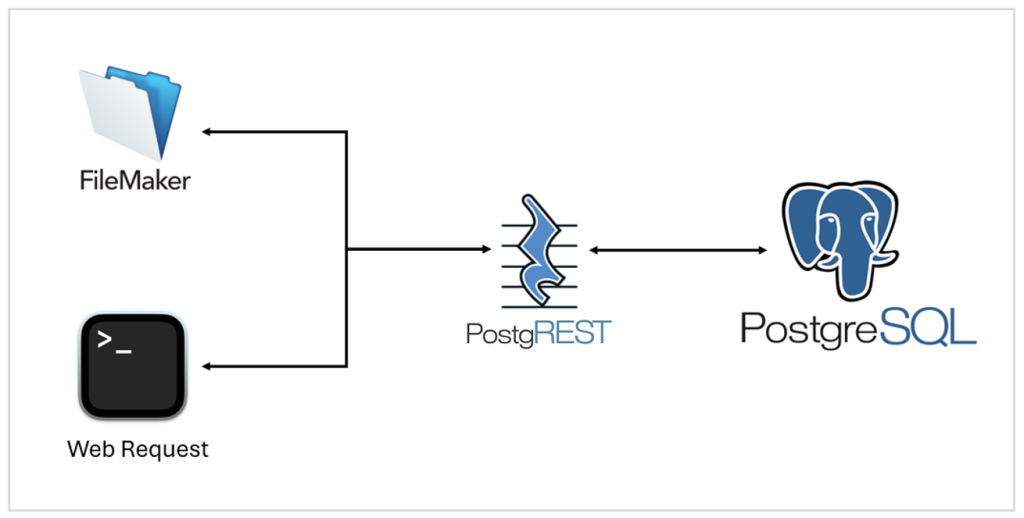
To address the synchronization delay, I researched and implemented PostgREST, an open-source tool that converts a Postgres database into a RESTful API. This setup allowed instantaneous read and write operations between the FileMaker and Postgres databases. Security measures, including authentication tokens, were added to ensure secure data access.
For spatial database reorganization, I consolidated fragmented layers, merged redundant data, and removed empty tables. I also created an enterprise geodatabase using ArcGIS Pro and Postgres, which served as the central repository for the arboretum’s spatial data. This geodatabase was registered with ArcGIS Server and configured to publish map and feature services, enabling seamless data integration with web mapping applications. By structuring the database efficiently, I ensured that it could support robust queries and future expansions.
Results
The database improvements achieved several significant outcomes. Synchronization between FileMaker and Postgres was streamlined, eliminating the one-minute delay and enabling real-time updates (Fig. 2). Another important achievement of the project was the consolidation of data layers into fewer but more informative ones. For instance, the garden paths, previously spread across five separate layers, were merged into a single, comprehensive layer. This new layer includes essential attributes such as material type and ADA accessibility. Additionally, new data layers were created for ponds and the garden boundary, further improving the quality and usability of the spatial data.
(Logos were obtained respective official websites)
Reflection
This project greatly enhanced my skills in database management and geospatial data organization. Implementing PostgREST deepened my understanding of RESTful APIs and their application in streamlining database workflows. Building the enterprise geodatabase and publishing services with ArcGIS Pro and ArcGIS Server provided hands-on experience in spatial database design and management.